This blog post is part of a series exploring the fascinating challenges I’ve encountered throughout my career.
Originally, the Splunk codebase was designed for on-premises installations, requiring manual setup via “tarball” on multiple data center machines. This approach demanded thorough knowledge of specific configurations and was notably time-consuming, especially for cloud deployments which could extend over weeks for each customer.
Moreover, Splunk’s development engineers lacked familiarity with the complexities involved in cloud setup and operation, leaving such tasks to dedicated cloud teams.
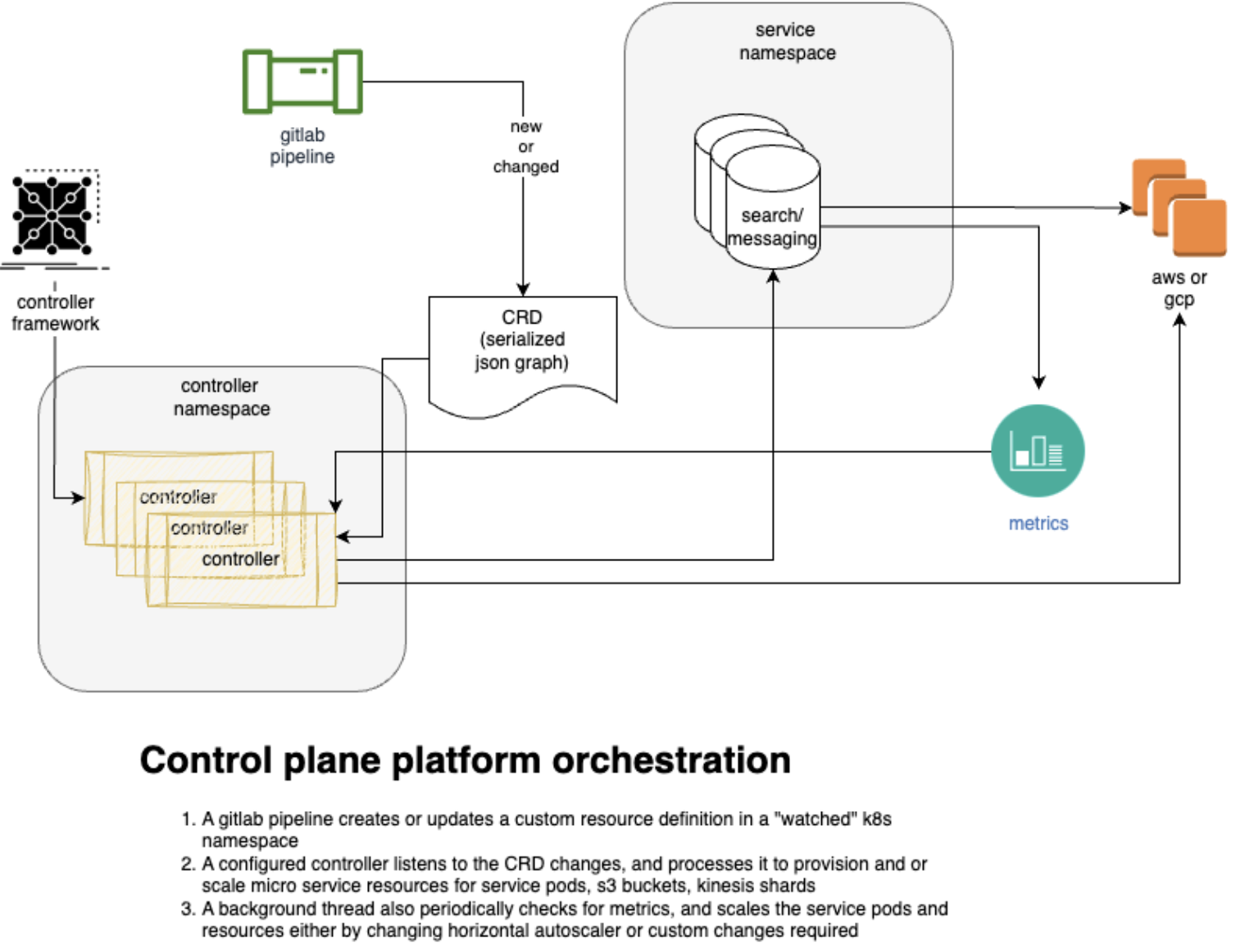
In response to these hurdles and aiming to modernize the Splunk core engine for cloud applications, we introduced a new framework named Maestro. Maestro streamlines the packaging and deployment process for Splunk in cloud environments through a microservices architecture alongside a cloud infrastructure configuration repository. This framework is complemented by developer-friendly command-line utilities and automated testing capabilities.
Thanks to Maestro, Splunk’s core engineering team could effortlessly establish their development environments, or “Sandboxes,” for experimenting with and refining Splunk’s cloud offerings. This advancement was achieved without necessitating deep understanding of cloud provisioning tools like AWS, Docker, and Kubernetes. Furthermore, Maestro’s applicability was broadened to facilitate provisioning and scaling for additional technologies such as Apache Pulsar and Apache Flink.
A key innovation of Maestro was its composability. Initially tailored for Splunk deployments, Maestro evolved into a versatile framework capable of managing and updating a suite of cloud resources. This flexibility was powered by a bespoke open-source graph library I developed, which underpins the Maestro Kubernetes controller.